Advanced Custom Aggregations
The [Settings > NetFlow > Advanced Custom Aggregations] menu can be used to create custom aggregations.
Advanced Custom Aggregations are aggregations that can be created by the user and for which it is possible to set a dynamic key field value (for performance reasons, max recommended value equals 3) and any metric (for performance reasons, max recommended value equals 6).
They are an evolution of Custom Aggregation which are available in the menu [Settings > NetFlow > NetFlow] and have built-in metrics such as Client Bytes, Client Packets, Flows, Server Bytes, Server Packets.
The aggregate defined in this way operates on data that arrives on an ongoing basis from the stream. Not on data already saved in Sycope. It works by plugging in data stream (netflow or netflowRaw), performs defined aggregations as data arrives and saves their results in its data file (result). The results are then available like any other data source for Sycope application objects (dashboards, nql, etc..).
After selecting the [Settings > NetFlow > Advanced Custom Aggregations] menu, a table with existing aggregations will be shown. For each object in the table, we can perform the following operations:
| Command | Description |
|---|---|
| Edit the aggregation parameters. | |
| Duplicate the aggregation. | |
| Export to a file. | |
| Delete the aggregation. |
Add aggregation / Edit aggregation
After clicking on the Add aggregation button or in the table on the ![]() icon, a window with the advanced custom aggregation creator will appear for adding a new aggregation or editing an existing one.
icon, a window with the advanced custom aggregation creator will appear for adding a new aggregation or editing an existing one.
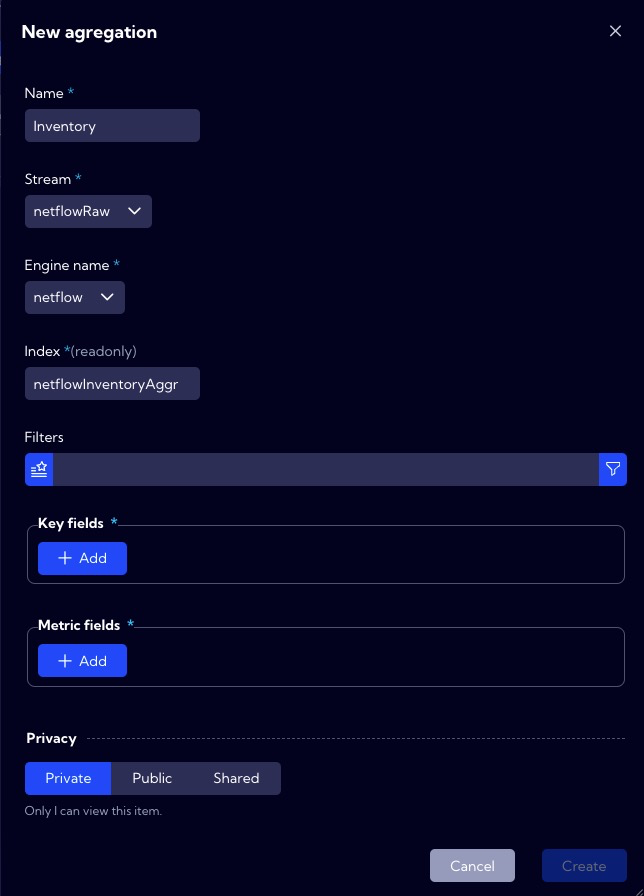
The following table describes the parameters that are available in the creator:
| Field | Description |
|---|---|
| Name | The name of the created/edited aggregation that will appear in the aggregation list table. |
| Stream | Selecting the data source for aggregation. |
| Engine name | Selecting the process feeding the aggregation. |
| Index | The name of the pre-aggregation as a data source. In the system, the data from it will be available under this name. |
| Filters | A filter in NQL format that will filter the data passed from the "Stream" for aggregation. |
| Key fields | List of data fields from the source after which the aggregation of the indicated fields will be performed. It defines a group of values in a Metric fields. |
| Metric fields | The fields whose values will be aggregated by the defined "Key fields". For each field, we can select the aggregation function in the "Deduplication strategy" field. |
Stream
| Name | Description |
|---|---|
| netflow | Data after de-dublication. The default strategy is 'first'. |
| nertlofRaw | Raw data before de-dublication. |
Deduplication strategy
| Name | Description |
|---|---|
| sum | The sum of all values in a group defined by key. |
| and | Calculates the bit AND operation on values in a group defined by key. |
| first | The first value in a group defined by key. |
| last | The last value in a group defined by key. |
| max | The largest value in a group defined by key. |
| min | The lowest value in a group defined by key. |
| none | Takes a random value from a group defined by key. |
| or | Calculates the bit OR operation on values in a group defined by key. |
Ungroup collection
Optional. If one of the Key Fields is a collaction, then we can unwind its values before aggregation.
For example:
A key field 'Countries' value is a collection ['PL','US','IT','GB'].
if Ungroup collection is empty then the input data will be:
[
{"Countries":["PL","US","IT","GB"],"fname":"John", "age": 83}
]
If the fiels in set in Unwind by key field field, then the (unwinded) input data for aggregation will be:
[
{"Countries":"PL", "fname":"John", "age": 83},
{"Countries":"US", "fname":"John", "age": 83},
{"Countries":"IT", "fname":"John", "age": 83},
{"Countries":"GB", "fname":"John", "age": 83}
]
When we click Save button, the message will appear asking for creating a data retention for the aggregation.
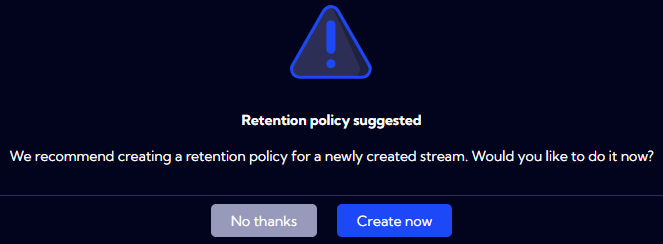
It is always good to define data retention for aggregation. Since pre-aggregation is executed at intervals, the retention helps to improved system performance and data storage optimization.
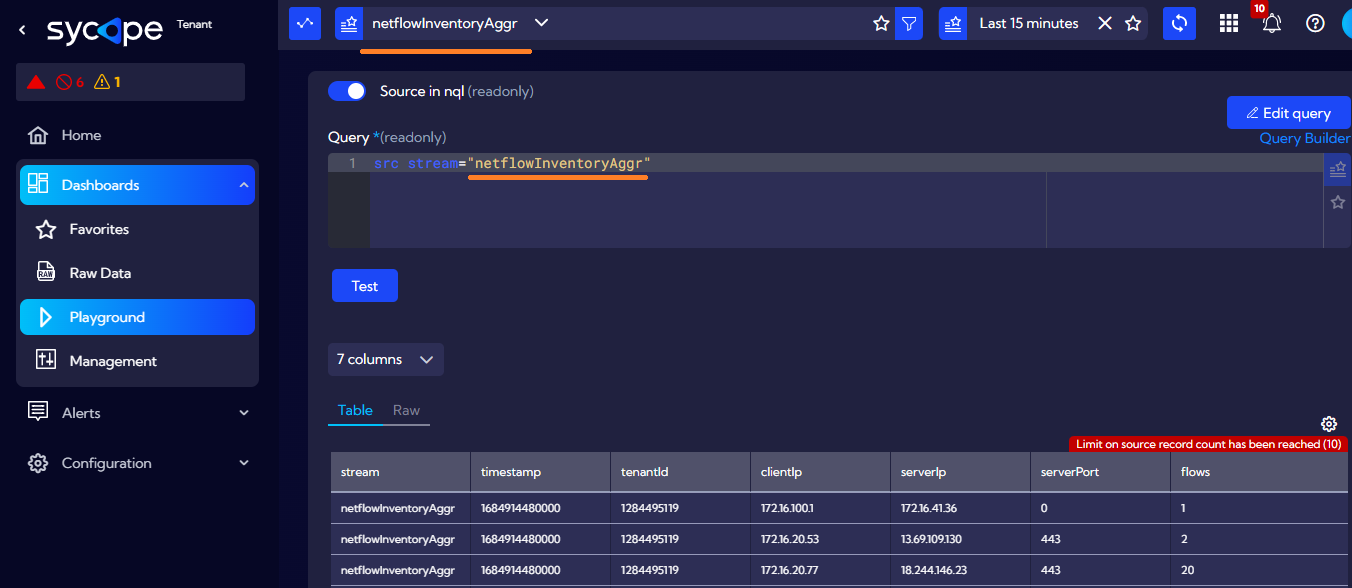
After saving, the aggregations will appear in a table and will be available in the system, for example, in the Playground, under the source name specified in the ”Index" field. The first data should be available about 1 minute after creating the aggregation.

Import aggregation
The Import aggregation button is used for importing a previously exported (![]() ) aggregation from the file.
) aggregation from the file.

After selecting the file, a window will show up enabling the edition of imported data before saving it.